To start, let’s take a look at the following code:
def process(xs: => Traversable[Int]) = xs.map(_ + 10).filter(_ % 3 == 0).map(_ * 2)
process function is just a chain of transformations on the given Traversable. Each of these transformations will create an intermediate traversable to be passed to the next transformation function. Given xs = Array(1, 2, 5), the manual tracing output would be:
1 is increased by 10 so transferred to 11 2 is increased by 10 so transferred to 12 5 is increased by 10 so transferred to 15 11 is filtered out because it is not a multiple of 3 12 is kept because it is a multiple of 3 15 is kept because it is a multiple of 3 12 is multiplied by 2 so transferred to 24 15 is multiplied by 2 so transferred to 30
In imperative programming style, this computation can be done “easily” with a while loop which transform each element of xs to the final desired value in one go. So no intermediate traversable will be created and this means less memory allocation. In this case, the manual tracing output would be:
1 is increased by 10 so transferred to 11 11 is filtered out because it is not a multiple of 3 2 is increased by 10 so transferred to 12 12 is kept because it is a multiple of 3 12 is multiplied by 2 so transferred to 24 5 is increased by 10 so transferred to 15 15 is kept because it is a multiple of 3 15 is multiplied by 2 so transferred to 30
How can we keep the compositional style (composing higher order functions like map, filter etc.) but without creating intermediate results to use memory more efficiently?
This can be achieved by using non-strict data structures. Non-strict (or lazy) data structures defer a computation until it is needed. In Scala, Stream is an implementation of non-strict sequence. Here is a simplified version of Stream implementation:
trait Stream[+A] case class Cons[+A](head: A, tail: () => Stream[A]) extends Stream[A] case object Empty extends Stream[Nothing]
As seen above, the main difference between Stream and other strict sequences such as List is that the tail is a function instead of a strict value. So, tail is not being evaluated until it is forced. Let’s play with our Stream data structure to see how it works.
First, let’s create a convenient apply function
object Stream {
def apply[A](xs: A*): Stream[A] = if (xs.isEmpty) Empty else Cons(xs.head, () => apply(xs.tail:_*))
}
Now let’s add a simple version of map and filter to our Stream trait.
trait Stream[+A] {
def map[B](f: A => B): Stream[B] = this match {
case Empty => Empty
case Cons(h, t) => Cons(f(h), () => t().map(f))
}
def filter(f: A => Boolean): Stream[A] = this match {
case Empty => Empty
case Cons(h, t) =>
if (f(h))
Cons(h, () => t().filter(f))
else
t().filter(f)
}
}
Now, let’s partially trace our motivating example:
Stream(1, 2, 5).map(_ + 10).filter(_ % 3 == 0).map(_ * 2)
Upon the invocation of the first map, Stream(1, 2, 5) is matched with the second case (line 4) so Cons(11, function0) is created. function0 notation denotes on a function which if it is invoked, it calls map(_ + 10) on the tail of the original stream. Next, filter function is invoked on the result of the first step which was Cons(11, function0). So it is matched with the second case (line 9). Since 11 is not a multiple of 3, it should be filtered out so else branch is executed. Therefore, function0 is invoked to be evaluated. So we enter again in the map function and again we match to the second case (line 4) and Cons(12, function1) is created. Upon executing filter on this intermediate result, it is again matched to the second case (line 9) but this time, since 12 is a multiple of 3, it is not filtered out (line 11). So Cons(12, function2) is created. Now, map(_ * 2) will be executed on this intermediate result and so on so forth.
As you see:
- Intermediate results are type of
Streamwhich only has its head evaluated and the rest is not evaluated. - The order of the transformations is the same as
whileloop.
This is why sometimes streams are referred as first-class loops [1]. It seems that we should use this first-class loop instead of strict collections whenever we have a chain of transformations. Is it true?
To answer this question, I benchmarked Scala standard Stream against Array from both memory and throughput aspects. The benchmark source code can be found here.
For memory usage comparison, I implemented MemoryUsage application and monitored the memory usage of different approaches with VisualVM.
I increased the size of data to 50 million elements to make the result more visible in VisualVM. Here is the result:
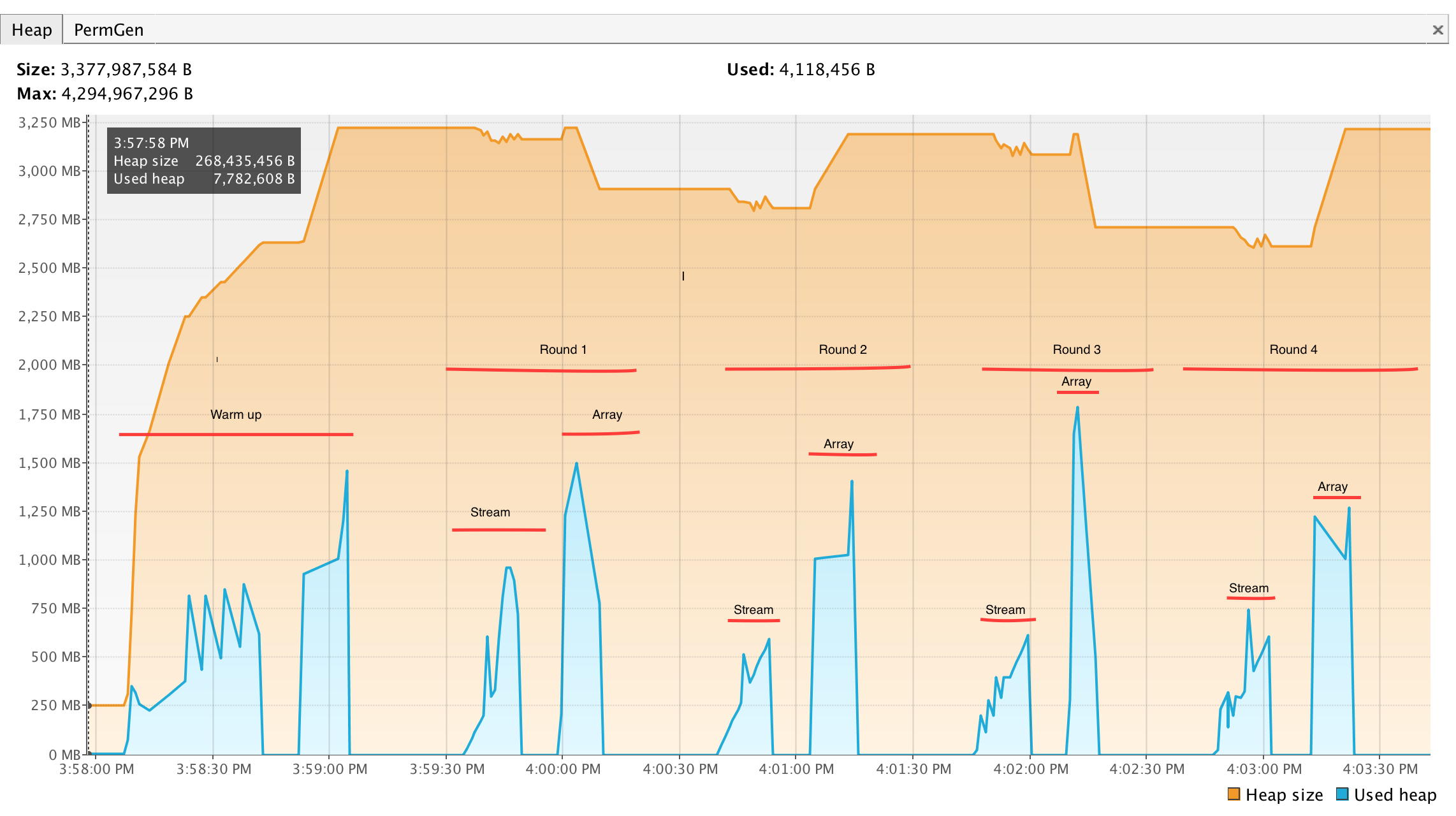
As seen, applying the aforementioned chain of transformations on Array needs considerably bigger heap size. However, when the size of data is smaller, the differences is less tangible. But memory usage is just one side of the coin. What about throughput?
Stream data structure heavily uses memoizing. This means that functions that are passed to the constructor are cached in lazy vals to prevent being re-computed. Although lazy values have been designed exactly for this purpose, comparing to vals, they have worse performance. So we can expect that the throughput of stream transformations is less than arrays (or generally strict collections). To experiment this, I did a micro-benchmark using jmh and sbt-jmh. I chose Array and Stream with 10000 elements with the following benchmark setup:
sbt "run -i 5 -wi 5 -f1 -t1 \"StreamingBenchmark\""
And here is the result:
[info] [info] # Run complete. Total time: 00:00:20 [info] [info] Benchmark Mode Cnt Score Error Units [info] StreamingBenchmark.streaming thrpt 5 880.009 ± 75.244 ops/s [info] StreamingBenchmark.strictProcessing thrpt 5 4078.819 ± 276.049 ops/s
As seen, given the previously mentioned transformation chain, Stream throughput is around 4 times less than Array throughput.
Conclusion
Although Streams eliminate intermediate collections upon transformations, it has considerably less throughput comparing Array (of course Array is optimised for traversing but I also executed the benchmark against other strict data structures like Vector and List and in all cases Stream has worse performance but with different ratios). Stream and other non-strict data types are great data structures but they should be used when their characteristics are really needed.
[1]. Chiusano P. and Bjarnason R. (2015). Functional Programming in Scala by Manning

Leave a comment